



近年来,数字人技术以惊人的速度发展,而视频换口型模型(Lip-Sync Model)作为其核心技术之一,正在彻底改变视频创作、直播、教育等领域的生产方式。无论是虚拟主播的实时互动,还是经典影视角色的“跨语言重生”,背后都离不开这项技术的支持。
本文深入剖析了“视频换口型”这一数字人核心技术,涵盖从音频特征提取、面部检测对齐,到生成模型推理与后处理合成的完整流程,并配以直观流程图与示例图像。我们汇总了目前最主流的13款换口型模型,逐一列出其核心特点、优缺点、开源状态及GitHub地址,最后通过对比表格呈现各模型在同步精度、视觉质量、实时性和可控性方面的差异。无论您是技术爱好者,还是自媒体内容创作者,都能借助本文快速选择最适合自己场景的音视频换口型解决方案。
技术解析:视频换口型模型如何工作?
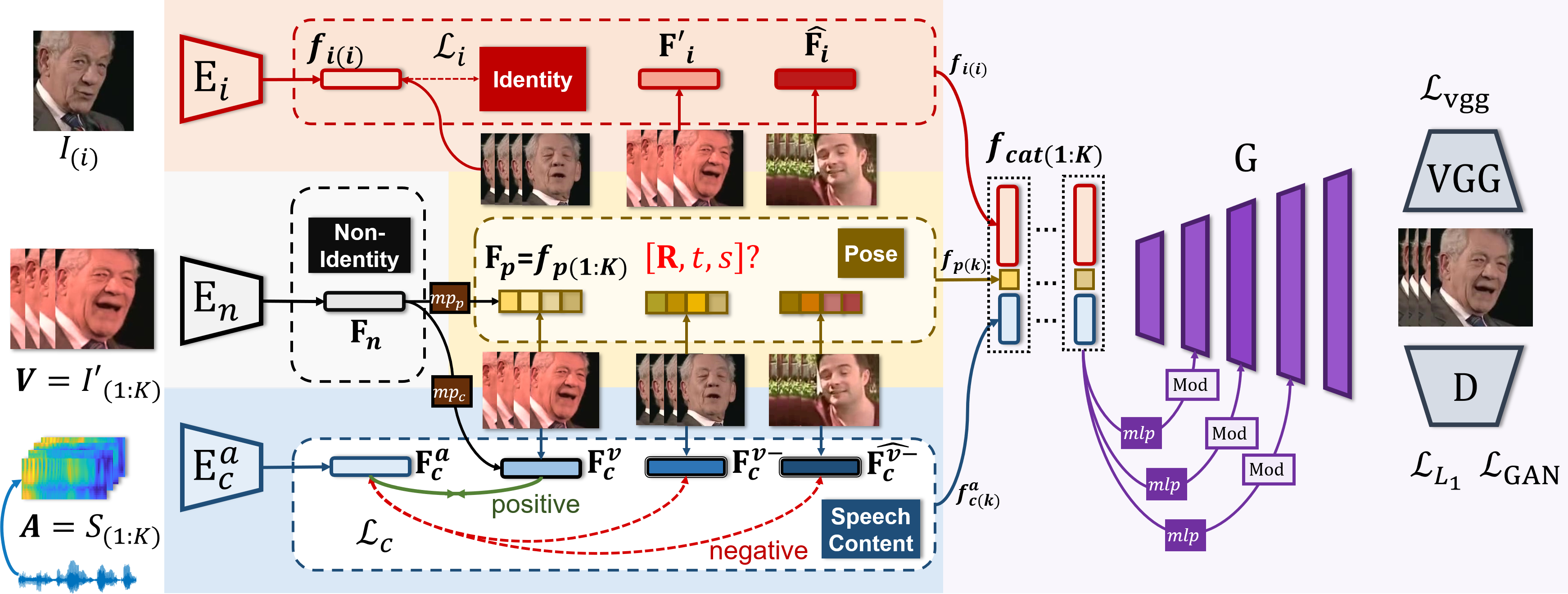
视频换口型(Lip‑Sync)技术旨在根据输入音频,生成与之高度一致的唇部运动,并将其无缝融合至目标视频中。其典型流程如下:
音频特征提取:将原始语音信号转换为MFCC或梅尔频谱图特征;
人脸检测与对齐:利用人脸检测算法定位并裁剪面部区域,实现关键点对齐;
模型推理生成:融合音频特征与面部特征,生成唇动或完整面部动画;
后处理与视频合成:对生成帧进行平滑、超分、多模态融合,输出最终换口型视频。
flowchart TD
A[输入视频] --> B[人脸检测与对齐]
C[输入音频] --> D[特征提取(MFCC/梅尔)]
B --> E[生成模型推理]
D --> E
E --> F[后处理(平滑/超分)]
F --> G[输出换口型视频]
主流模型盘点与对比分析
开源模型
以下模型均已在GitHub开源,可以直接集成或二次开发:
国内主流模型
技术突破与挑战
从“静态口型”到“动态表演”
Loopy和OmniHuman-1通过扩散模型实现了表情、肢体与语音的协同,解决了传统模型“只有嘴动”的割裂感14。
EchoMimic V2引入音频-姿势动态协调策略,支持半身动作生成,大幅提升沉浸感10。
中文适配的难点
中文的声调与连读特性对唇同步提出更高要求。Loopy因针对性优化中文语境,效果显著优于LatentSync15。
开源与商业化的平衡
开源模型(如EchoMimic V2、AigcPanel)推动技术普及,但部署门槛高;
商业产品(如HeyGen、Captions)简化操作,但依赖订阅制盈利89。
应用场景与未来展望
娱乐与营销:虚拟主播(如B站“洛天依”)通过Loopy实现24小时直播;品牌利用HeyGen生成多语言代言人,降低跨国营销成本19。
教育与医疗:PersonaTalk可生成虚拟教师,根据教学内容调整表情,提升学习体验6。
影视工业:OmniHuman-1支持快速生成角色预演视频,缩短制作周期4。
未来趋势:
多模态融合:结合语音、文本、手势实现更自然的交互;
低门槛化:轻量化模型降低硬件需求,如Heygem支持1080Ti显卡离线运行7;
伦理与安全:需防范深度伪造滥用,部分模型(如PersonaTalk)已限制开放权限
更多技术请关注-公众号和小程序


评论区